How text indexes work
Introduction
So what is an index anyway? It is a system which provides a fast way of searching for documents. The indexed documents can be books, web pages, or learning objects in an LMS. Without an index, a search engine would have to look through every single document for a given search word, which would not be feasible.
However, indexes make searches fast, but updates to documents, and creation of new documents are somewhat slower. This means that indexes are great for places where searches occur significantly more often than changes to the documents. In order to make searches fast, indexes use data structures called trees, because they offer great ways of findings things fast.
Let’s assume our documents are web pages, so our searches will be much like searches in an engine such as Google. We’ll take a look at how we’d use an indexer in order to be able to find web pages based on search terms (or words).
We’d like to be able to search for words inside the body of the web pages, inside their titles, and inside their URLs. However, when we search, we expect the indexer to give us back only URLs and Titles. Our browser will know how to get to the web page with that information.
This means that the indexer will build an index (a tree structure) for each of these, URL, Title, Full text (the content of the web page). Here’s what they’d look like:
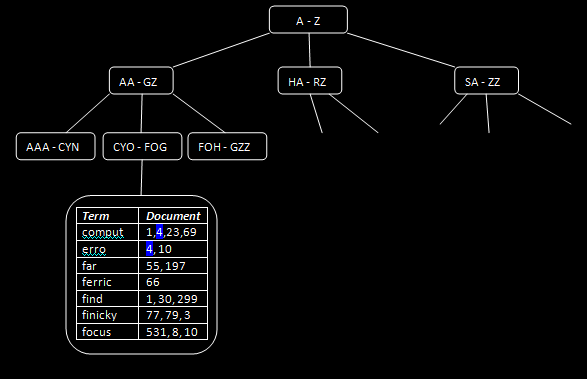
So basically, each of the URL, Title, Full text, will have one of these trees built for them. At the bottom of the tree, each table will contain modified versions of the words contained in the URL, Title, Full text, along with a document id, assigned specifically at indexing time by the indexer. Since we only want the URL and Title to be returned by a search, we will tell the index to store only these two fields in their entirety; the index will NOT contain the Full Text of any web page anywhere.
So we have decided that:
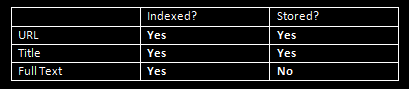
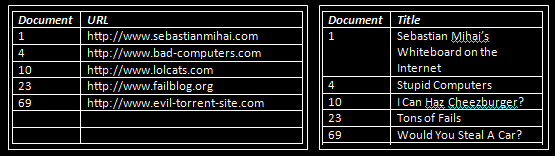
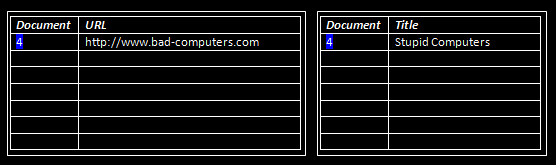
The URL and Title, however will be stored in plain tables like such:
Indexing, a.k.a. getting stuff in the index
Let’s take a look at how a web page gets indexed. Without going into much detail, this is the job of the so-called crawlers, which move from link to link on the web, looking for new web pages to index. Let’s assume the web page that has just now been discovered has the following fields
URL: http://www.bad-computers.com
Title: Stupid Computers
Full Text: Computers make many errors, resulting in erroneous computability.
Analysis, a.k.a. breaking down text into terms
For this web page, the indexer will assign a document id of 4. Let’s look at how the Full Text field will be broken down into terms. It will be passed through a series of filters. Terms are delimited by quotes in this example:
(apply a lowercase filter)
(apply filter that removes punctuation)
(apply filter that removes extremely common prepositions)
(apply filter which splits into multiple terms whenever it finds a blank space)
(apply English word root filter)
(apply filter that removes duplicate terms)
The terms in the URL and Title will be broken down in a similar fashion.
Our term lists for each field
After this, the indexer “finds” the place of each term by traversing the tree downward, and finding the proper alphabetical location for each term. So after looking at each of the three fields (URL, Title, Full Text), they've been split in the following terms (note that these can vary):
URL: bad comput www
Title: stupid comput
Full Text: comput make many erro result
Let's look at what these have added to our tree structures (keep in mind that the indexer has assigned the id of 4 to this document):
URL index after insertion
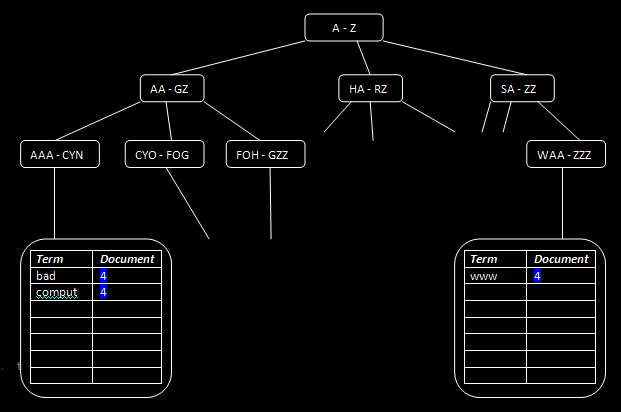
Title index after insertion
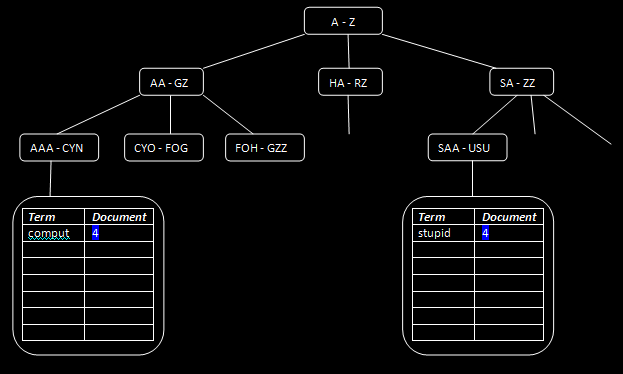
Full Text index after insertion
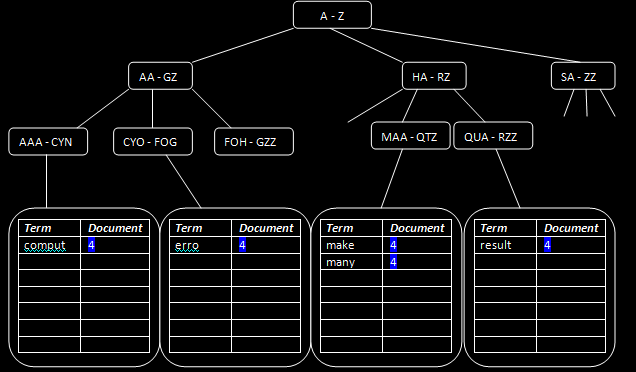
Stored Fields
Searching, a.k.a. asking the index for document results
We have now seen how the indexing operation happens. The indexer (or indexing service) pretty much breaks down fields (such as URL, Title, Full Text) of a given document, in such a way that retrieval by term (or word) lookup will be easy.
Using our web page indexer example, let's see what happens when a user looks up the term "Theory of Computation".
Analysis
Note: In practice, the analysis performed when indexing is similar to the analysis performed when searching.
"Theory of Computation"
"theory of computation"
"theory computation"
"theory" "computation"
"theor" "comput"
The indexer will then have to look in the three indexes for these two terms, "theor" and "comput".
Searching for the term "theor"
The first term of the query is now searched through each of the indexes (URL, Title, Full Text). Here's how the search looks in the URL index:

Obviously, the term is not found in any of the three indexes.
Searching for the term "comput"
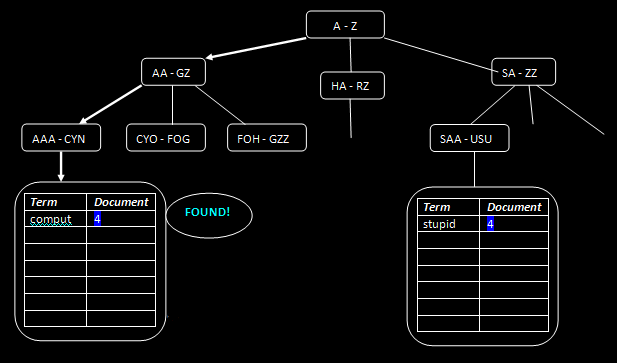
The term is found in the Title index. We are assuming here that the indexer will look in all possible (URL, Title, Full Text) indexes for each query term. In practice, different search queries may only have some of the indexes selected as candidates to be searched. An example of this would be an "advanced" search where we are only searching by Title.
Going back to our "comput" term, it has been found in the Title index, and we now know that it exists in document 4.
Retrieving stored fields
So now we know that one of our search terms originates from document 4.
Remember our stored fields? We're only storing URL and Title. Here are the tables of stored fields again:
Using the document id, we can quickly search these tables and get to the respective values for URL and Title.
Returning search results
That's about it. The indexer will return something like:
URL: http://www.bad-computers.com
Title: Stupid Computers
This eventually ends up as a search hit in your browser. Obviously, the example above is extremely simple compared to real-life scenarios. Here are a few questions for further reflection on this subject:
1. Why is the Full Text field not stored?
2. How would the indexer handle multiple languages?
3. How would it calculate relevancy when multiple documents contain multiple search terms?